The data side of leaving no one behind
In this paper we look at lessons learned from data landscaping at the national level, and examine how it can be used to inform decisions about poverty eradication and ensure no one is left behind.
Downloads


One of the cornerstones of Development Initiatives (DI)’s commitment to the Leave No One Behind agenda is that in order for people to count, you need to count people. Births need to be registered, visits to health facilities need to be recorded, progress through school needs to be monitored. Service delivery requires good public administration which requires good data. In high income countries these infrastructures are taken for granted. This is not the case in low income countries, particularly in fragile and conflict-affected states.
When DI opened its first office in East Africa in 2011, a new dimension was added to our work. In addition to analysing global aid flows we began focusing on the role of national and subnational data in informing decisions impacting on poverty eradication. We explored the added value of joining up different official datasets at district level in Uganda, [1] community-based resource tracking [2] and citizen-generated data [3] in both Kenya and Uganda. We mapped primary data sources [4] and began to develop a methodology [5] for analysing data ecosystems. We shone a light on community information systems [6] and proposed a new methodology for monitoring civil registration and vital statistics. [7] We also broadened the scope of our work, exploring the political economy of data. We developed a more holistic approach to our data ecosystem work, [8] participated in formulating the Africa Data Consensus [9] and argued for a more inclusive approach to framing the national statistical system. [10] We championed the importance of both institutional and systems interoperability: [11] work that led to the first partnership between the previously separate worlds of official statistics (the UN Statistics Division) and the broader data revolution (Global Partnership for Sustainable Development Data). [12]
In May 2017 we travelled to Zimbabwe for our first contract under a long-term agreement with UNICEF’s Division of Data Research and Policy. UNICEF had a requirement, within its Data for Children Strategic Framework, [13] to review its priorities and investments in driving the demand, supply and use of data at country and regional levels. Under this agreement we went on to fulfil contracts for country offices in Bangladesh, Nigeria, South Sudan, Uganda and the United Arab Emirates. A similar exercise, funded by the UK Foreign, Commonwealth and Development Office, was completed virtually in Nepal and a mapping focusing on disability data was conducted in Uganda [14] as part of the Inclusive Futures programme. [15]
Out of this work we have developed an approach that we call data landscaping. Its scope covers the political economy of data within a country; the structures and standards that govern the collection, production and sharing of data; the information systems themselves; and the culture that drives the demand for, and use of data.
This discussion paper is the first of a series produced as part of our work on data use. For more information, read the next paper in the series, Data disharmony: How can donors better act on their commitments?
Figure 1: Data landscaping
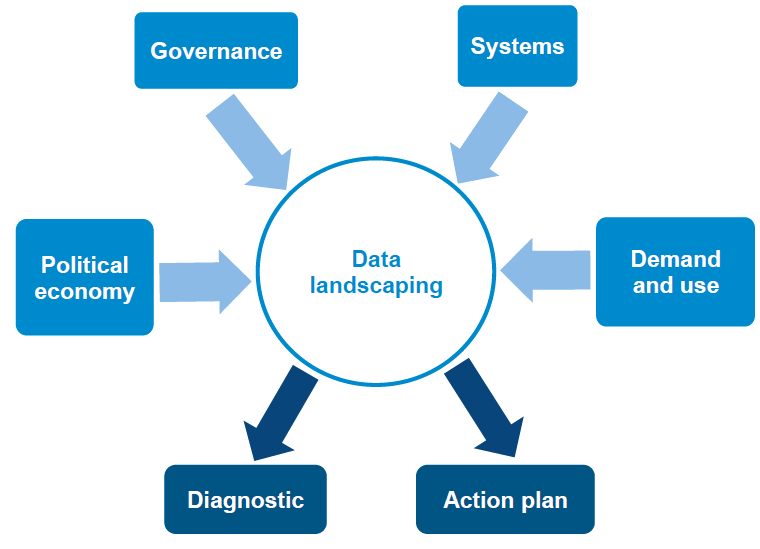
Diagram showing DI's data landscaping approach: 'political economy', 'governance', 'systems' and 'demand and use' are inputs; 'diagnostic' and 'action plan' are outputs.
The work itself involves literature reviews of legal, policy and planning frameworks; key informant interviews with data producers and data users; visits to schools, clinics and local government offices; assessments of both the design and deployment of information systems; mappings of primary data sources against national and global indicator frameworks; and the identification of data duplication and gaps. It concludes with an action plan that makes pragmatic recommendations on national policies and investments to be prioritised.
While much of the landscaping work we have done has been on commercial contracts, we have developed our own vested interest in this work as it resonates with our strategy to strengthen data ecosystems to increase the collection, sharing and use of data. We have therefore compounded our learnings from contract to contract and approach each new exercise with a transparent set of prior assumptions that we are continually putting to the test and refining. Every country has its own unique political economy, but that is not to say there are not many similarities. This paper is our first attempt at mapping out this common ground at the national level. A second paper currently being prepared will review progress made by international actors in harmonising their activities and aligning their investments with national priorities.
Since 1981 Denmark has been able to conduct population and housing censuses without hundreds of enumerators having to knock on doors with lengthy questionnaires. This did not happen overnight. Over 15 years, legal frameworks were established, one common unambiguous identity system was introduced, population and building registers were built and underpinned management information systems across the full extent of public administration. This is an ecosystem that enables the government to take well-informed decisions and for citizens to hold it to account. [16]
Many high income countries are now following in Denmark’s footsteps. This is not the case for the majority of middle and low income countries. The advice and support they continue to receive guide them towards a regime of a 10-yearly census and intermittent small sample household surveys.
In April 2017, the Ghana Statistical Service co-hosted a National Data Roadmap Forum in Accra. A team from Statistics Denmark attended, who had been invited to talk about the benefits of the Danish approach. Their presentation was met with great enthusiasm and a partnership between the two institutions has now been established. The Ghana Statistical Service is now set on a course to, eventually, derive population-based statistics from administrative data. This will be no easy journey.
Over the past decade much progress has been made, including in conflict-affected states such as Somalia and South Sudan. Most countries now have a dedicated cohort of statisticians, and many have graduates with analytical and statistical degrees from their own universities. ICT infrastructures in capital cities have developed in leaps and bounds. Most countries now have a national data portal of sorts. And most have established a health management information system and conduct an annual school census. Many countries are reviewing their legal and policy frameworks that provide powers to their data collectors as well as protection to their citizens.
Perhaps most encouragingly there is a growing body of dedicated civil servants – in local and national government – who recognise the value of data. Our experience in rural Uganda back in 2015 epitomises this passion:
“We started by looking for the latest school enrolment figures and spoke on the phone to the Katakwi District Education Officer. She had the data in front of her, but no internet connection. She offered to drive 60km to the neighbouring town of Soroti to send us an email. We persuaded her not to, and she dictated a spreadsheet of data, over the phone, for all 74 primary schools under her jurisdiction.”
Digital Impact, 2015. Adventures in the Data Revolution: Collecting Ugandan Data. Available at: https://digitalimpact.io/adventures-in-the-data-revolution-getting-to-grips-with-data-in-uganda
Household surveys, funded by the World Bank and USAID, were introduced into developing countries as key data collection tools in the mid-1980s [17] (followed by UNICEF’s Multiple Indicator Cluster Survey (MICS) [18] a decade later [19] ). In the countries in which they were introduced they filled a vacuum, providing more reliable demographic and socioeconomic data than had previously been available. They remain to this day the dominant, most widely regarded source of development statistics.
However, a combination of sample design and cost [20] means that while they produce reasonable national estimates, surveys cannot provide sufficiently disaggregated data of use to local government. The communications and policy departments in UNICEF country offices, for example, make great use of MICS data, but their teams working in the field – in health, education, nutrition and social protection – find it insufficiently granular to be of much use. [21]
A 2013 study went further and argued that surveys miss out some of the most vulnerable communities completely:
“In developing countries, assessments of progress toward development goals are based increasingly on household surveys. These are inappropriate for obtaining information about the poorest. Typically, they omit by design: the homeless; those in institutions; and mobile, nomadic, or pastoralist populations. Moreover, in practice, household surveys typically under-represent: those in fragile, disjointed households; slum populations and areas posing security risks.”
Carr-Hill, R. World Development. ‘Missing Millions and Measuring Development Progress’. 46, 2013, pp. 30-44, www.sciencedirect.com/science/article/abs/pii/S0305750X13000053
There is a growing consensus among all development actors that while surveys still have an important role to play – in quality assurance and filling gaps, for example – there is more capacity now available for administrative systems to begin to provide more comprehensive and timely data. Unfortunately most of this consensus remains rhetorical. Scan the Sustainable Development Goal (SDG) metadata database [22] and you will find many references that recognise administrative data as the ideal data source, yet the curators of most indicators are happy to rely on survey-based estimates.
With a few exceptions – notably some deployments of the district health information system (DHIS2) – most administrative systems still deliver incomplete, inaccurate data. Despite the progress being made already referred to, they lack sufficient ICT infrastructure, mature bureaucratic standards and norms, and technical and human capacity.
Most governments and donors operate within three-to-five-year policy and funding cycles and expect a return on investment within this period. Nationwide administrative systems need development cycles much longer than this to incubate and mature. As a result they remain underfunded, producing poor, generally unusable data in a seemingly perpetual cycle of neglect, while global and national curators of statistics continue to respond to immediate data needs using traditional surveys.
A key part of our landscaping work is to map all primary sources of data and to track the flow of data from point of collection to final use. This work reveals the complexity of a country’s entire data landscape. Uganda’s National Information Technology Authority maintains a Portfolio of Government System Services [23] that lists over 300 information systems. In most sectors there are systems covering registers, management information, finances, logistics, HR and knowledge sharing. Many systems have been developed nationally with no subnational rollout. Many started with good intentions but lacked financing. Many are poorly maintained. Most contain incomplete data.
Even in sectors with relatively mature systems, complexity is common. It is not unusual, for example, for standalone systems serving immunisation, malnutrition, malaria, tuberculosis and HIV and AIDS to sit outside the mainstream health management information system.
One of our first big learnings was that while most government officials (and some development partners) recognise the importance of building sustainable data infrastructures throughout the country, the lack of ICT infrastructures, finances, technical and human capacity make this extremely difficult to achieve. Limited resources are thinly spread across too many systems resulting in second-best solutions across the board.
Influenced by our field visits away from the upstream (from national to global) focus of capital cities, we have over time developed a common set of recommendations that we have repeated with increasing confidence. National data infrastructures need to be built from the bottom up. Primary schools, clinics and local government offices are the most widespread physical embodiments of public administration and service delivery. We have therefore argued for the largest part of investments to be concentrated in the digital transformation of these three areas: health management information covering facility-level service delivery; education management information covering the performance of primary schools; and birth registration including the issuance of a legal identity. In this way, a robust national backbone can be constructed that provides both a shareable technical infrastructure and a culture of data use that can catalyse the development of other systems.
Figure 2: A foundational data ecosystem
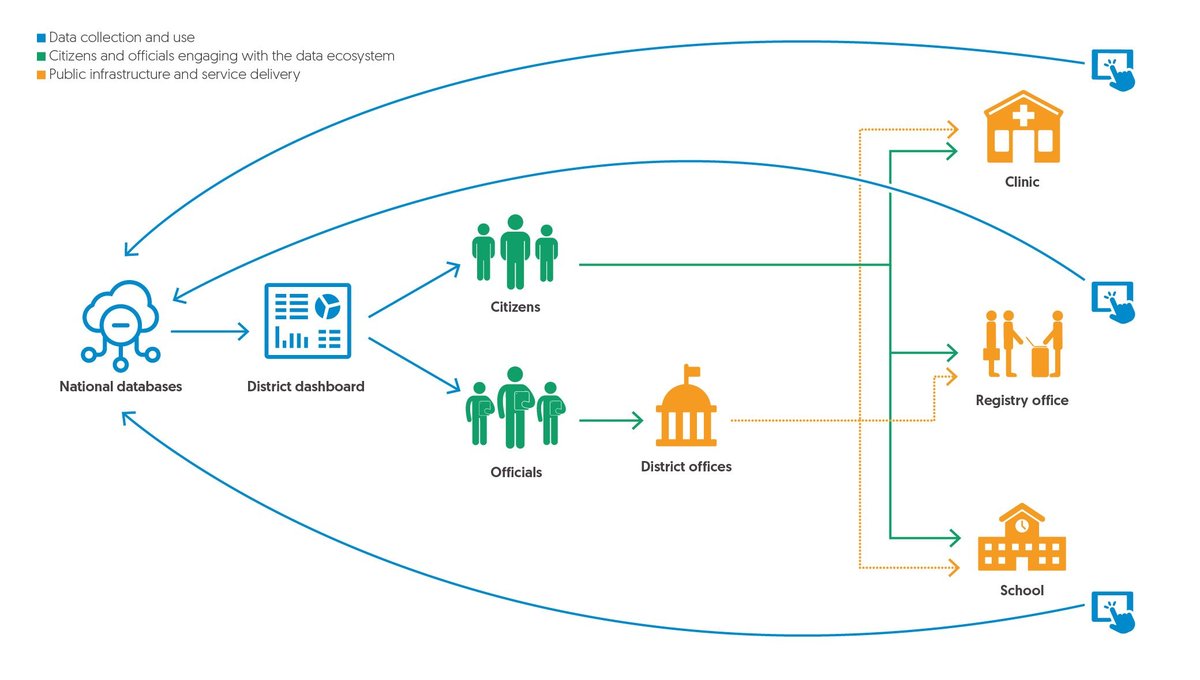
Diagram showing data collection and use, citizens and officials engaging with the data ecosystem and public infrastructure and service delivery: national databases are connected to district dashboard, which is connected to citizens and officials; officials are connected to district offices, which is connected to the clinic, registry office and school; citizens are directly connected to the clinic, registry office and school; there is data collection at the point of service delivery at the clinic, registry office and school, which connects back to national databases.
Source: Development Initiatives, 2020. Digital civil registration and legal identity systems: A joined-up approach to leave no one behind. Chapter 4.
DHIS2 is arguably the most successful administrative system built for low and middle income countries. Its core module – a facility-level health management information system – is operational in 60 countries. Its patient-level tracker is also being introduced, as are its COVID-19 surveillance and vaccination modules. It is built on a simple, robust platform with built in mobile connectivity. In most countries, however, clinics still log their day-to-day work in paper registries and an unwieldy paper-based monthly aggregation of records is submitted to a district office for keying into a national database. By equipping facilities and training health practitioners with tablet-based digital capture – a relatively modest expense – not only will the quality and timeliness of data be improved but health workers will be able to review and use their own data.
Most low income countries claim to have an education management information system. In practice they have what is better described as an annual school census which counts the number of classrooms, desks, teachers and pupils, but has nothing to do with performance or learning outcomes. Most primary schools do maintain a suite of rudimentary paper-based administrative records: in particular a register of pupils, attendance records and learning outcomes. Digitising this data is a substantial challenge. In Bangladesh, for example, an education specialist estimated that fewer than 5% of primary school headteachers currently have the skills to use a spreadsheet. In Zimbabwe every primary school had been issued with a computer but only 52% of them had electricity. But times are changing. The level of data literacy among new generations of teachers is increasing, and schools in towns and larger villages are starting to benefit in most countries from one form or another of electricity as well as internet connectivity.
Despite a surge in global campaigning on civil registration and legal identity, progress in the digital registration of births has been very slow in many low income countries. This has not been helped by the commercialisation of identity systems and the hard sell on biometric products that has led a number of governments to adopt systems that are difficult to deploy and maintain. Investing in the digital registration of births as the foundation of a population register is a responsibility that governments cannot ignore as this foundational identity underpins an increasing number of services of benefit to both state and citizen.
Putting forward a recommendation to prioritise these three core systems in front of government-wide and multi-sector validation workshops is a tricky challenge. How does one respond to those championing agriculture and food security, water and sanitation, climate change, social protection and public financial management? Of course there are national information systems that are an essential part of these sectors, and some might already be deployed down to local government level. It remains our considered opinion, however, that building strong foundations for administrative systems that will stand the test of time requires those at the coal face of service delivery to appreciate, collect and use digital data. Clinics, primary schools and registry offices are a good place to start to build a core community-based infrastructure and culture.
In 2012 the UN Task Team that was mandated to learn the lessons of the Millennium Development Goals and frame the post-2015 development agenda (the SDGs) recommended that a 25-to-35-year time horizon was the realistic target to “accomplish major transformations”. [24] The High Level Panel in May 2013 recommended that “targets in the post-2015 agenda should be set for 2030. Longer time frames would lack urgency and might seem implausible…” [25]
In February 2015 the report of the second Global Public Consultation on SDG indicators recommended that, “based on discussions with senior statisticians, we believe 100 to be the maximum number of global indicators on which NSOs can report and communicate effectively in a harmonized manner.” [26]
The scientifically proposed SDG monitoring framework of 100 indicators to be met by 2050 was given short shrift by the political decision-makers and replaced with more than double [27] the number of recommended indicators to be met in half the time. We have experienced two consequences of this decision in every country we have visited.
The first is that the SDGs are seen as a global commitment which is measured in global databases. The upward flow – from national to global – of monitoring statistics is prioritised at the expense of local data that is of more relevance to those people responsible for ensuring that the targets are actually met. Thus, statisticians are under pressure to accept that it is more important to calculate the maternal mortality rate than put in place reliable data on the services available for pregnant women.
The second is that national government officials have succumbed to a polite dishonesty: few approach the SDGs with the conviction espoused by UN agencies in particular, and the development partner community in general. While all may aspire to the goals, few believe that many of the targets are realistic. Africa after all has its own, SDG-linked, Agenda 2063. [28]
The term 'glocal' – reflecting both global and local considerations – has become part of the lexicon of the 2030 Agenda. According to the UN Development Group “‘Glocalizing’ the agenda within a country is an imperative if the SDGs are to be realized with no one left behind in the 2030 timeframe.” [29] This is a nice idea but when it comes to data it is not only unrealistic but also misleading in that the global monitoring framework actually undermines investment in local data systems.
In none of the countries in which we have worked has local health, education or civil registration data been used to derive SDG indicators. Even in the United Arab Emirates where the health management information system does produce credible statistics, these are not used by the global institutions, such as the World Health Organization, responsible for curating indicators. [30] SDG methodology is now locked in to proxy algorithms and there is no incentive for governments or donors to prioritise investments in local systems.
Much is spoken these days about “data-driven decision-making”. There is no such thing. Politicians may absorb information from the press or a report that will inform their decisions, along with a range of other political considerations. The fact is there is very little use of data in many countries, even less demand and thus little recognition of the importance of data and the need to invest in its production. This is particularly the case in low income countries where politicians are keen to demonstrate the benefits that their constituents derive from their efforts. Roads, hospitals and schools are visible and win votes. Data does not get you elected.
Given that the fundamental premise of our landscaping work is that data is important, the lack of demand – which you cannot just wish into existence – presents us with a major challenge in proposing solutions that are realistically achievable. This lack of demand affects governments’ commitments to enabling legal and policy frameworks and, most importantly, to the resources they are prepared to commit to strengthening national data infrastructures.
National statistics offices (NSOs) as a rule have traditionally tended to be cautiously conservative institutions: fierce defenders of the processes and standards of official statistics. With the explosion both in the volume of data now available and the technologies available to process it, NSOs face existential challenges to their role as sole gatekeepers of their country’s data assets. While the role of new sources of data from the private sector, civil society and academia is more often than not overstated, there is increasing pressure on NSOs to adopt a more inclusive approach in their definitions of the national statistical system.
NSOs have traditionally depended on the census and household surveys for all their socioeconomic statistics. In all the countries we have studied they have little access to, and even less influence over, the administrative data emanating from line ministries and big data sources – phone call data records and satellite imagery – owned by the private sector. The NSO does however remain best placed to both lead and coordinate this changing data landscape. For this to happen four things are required:
Firstly, it needs revised legal powers to govern, access and use all relevant data. Many countries are already in the process of revising their statistics legislation to achieve this.
Secondly, it needs the political authority to lead and coordinate a wide range of institutions. Where the NSO sits in government varies from country to country. In many countries they are semi-autonomous agencies. The independence this gives them on the one hand allows for a degree of objectivity free of political influence. On the other it denies them a seat at the central table of national decision-making. As administrative data becomes more usable, the need for the NSO to engage in government-wide planning becomes more important.
Thirdly, it needs the capacity and culture to engage constructively with all producers and users of data. Statisticians need to become data scientists, embracing, for example, different sources of data and extracting value from incomplete data. They need to have mastery over the anonymisation and security of data they hold. They need to share the resultant aggregated statistics responsibly without being unnecessarily defensive, as many are, about them being used inaccurately or out of context. They need to support ‘non-official’ organisations in adopting standards and methodologies which will lead to their data collection efforts being approved and certified.
Fourthly, it needs a clear roadmap to implement this transition. Most countries have adopted a standard model: the National Strategy for the Development of Statistics (NSDS). Despite having been modified to take on board the broader context of the data revolution, the generic template on which client countries build remains, in our experience, primarily focused on high-level concerns relating to producing national statistics. [31] If countries want to aspire to a 21st century vision of a robust data ecosystem the NSDS will need to provide a practical roadmap towards building sustainable local capacity.
The legal and political challenges addressed above have technical implications for the way in which data is stored and used. Turning data into information requires context and in many instances the context is provided by joining up or comparing different datasets. In the countries in which we have worked this rarely happens and we have observed common problems that can be solved by common solutions.
Firstly, the biggest obstacle to interoperability is not technical, but institutional. If people are not capable of having constructive, collaborative discussions with each other their systems do not stand a chance. Establishing government-wide and cross-sectoral forums and working groups is the first step. Yet there is a danger, as we discovered in attending a session of the UN data working group in Bangladesh, of such forums limiting themselves to show-and-tell sessions – thus normalising competitive siloes – without having serious conversations about coordination.
Secondly, given that few institutions are aware of what the others are doing there is a need for a central repository of knowledge. We recommend establishing and maintaining a national indicator framework which maps the country’s statistical needs against all primary data sources and highlights both gaps and duplications.
Thirdly, for systems to speak to each other they need to understand each other’s language. A central data dictionary, linked to the indicator framework, provides a standard framework in which to describe and define the format, syntax and methodology of each data element. In 2015 the Ugandan Bureau of Statistics published a National statistical metadata dictionary [32] which, to our knowledge, has unfortunately not been kept up to date, but is exemplary in its conception.
Table 1: Data fields in Uganda’s metadata dictionary
| Structure of Uganda’s National statistical metadata dictionary |
|---|
| Indicator name |
| Indicator definition |
| Standard classifications and manual followed |
| Unit of measure |
| Disaggregation |
| Compilation practices |
| Sources of data |
| Computation method |
| Accessibility and availability of data |
| Periodicity of production |
| Comments and limitations |
| Sources of discrepancies between national and global figures |
Source: Ministry of Health Knowledge Management Portal (Uganda). [33]
Fourthly, progress is best demonstrated in the first instance by simple, pragmatic steps. This could be a local government dashboard which provides citizens with an overview of the availability and performance of different services in their district, delivered on paper to village notice boards.
With solutions such as these in place – and the accompanying experience and culture – it is more likely that linking servers, deploying APIs and physically integrating systems will succeed.
The first manifestation of the data revolution emerged in high income countries in the form of the open data movement. Supported by a well-connected citizenry, civil society organisations and transparency initiatives successfully called on governments and others to open their data vaults to better account for their actions.
Take up in low income countries was initially slow. The argument, often presented in a moralistic tone, that opening up data would expose corrupt governments to their citizens was not received very well by many NSOs. These same governments, however, were often keen for their data to be used and national data portals of varying quality began to emerge. The argument that opening up government data is good for the economy was met with even less enthusiasm. It is multinational enterprises who are best equipped to commercially exploit open data at the expense of their weaker less data-savvy national competitors.
The second manifestation was the explosion of systems producing big data accompanied by the emergence of artificial intelligence (including machine learning, natural language processing and algorithmic problem solving) and now championed by the neoliberal ideology of the Fourth Industrial Revolution. In the words of the World Economic Forum “the 4IR represents a unique opportunity for African countries to leapfrog over development hurdles with the help of technology.” [34]
The idea that technological innovation that exploits big data is the solution to low income countries’ data problems is a dangerous concept currently gaining currency in development circles. The data captured in a child’s birth registration, a patient’s health record and a pupil’s progress through school are the kinds of inputs needed for machine learning to develop useful algorithms. In low income countries this data does not exist in sufficient quantity or quality to be of any use. Yet every month a new data science challenge is launched by donors who appear not to grasp the fact that the data needed for artificial intelligence to work comes from the very systems that artificial intelligence wants to replace.
Technological innovation as espoused by most of its advocates assumes that a digital ecosystem already exists. It is, however, establishing these core foundations – digital transformation – that remains the priority. Local facilities need input devices to capture data. These devices need to be charged and have access to the internet. School teachers and nurses need skills in basic data literacy. The data ecosystem needs solid foundations and in many countries these are still being built.
Those innovative systems that are being deployed are facing increasing challenges over concerns about the storage and use of personal data. Biometric data from identity systems has fallen into the wrong hands. [35] Foundational identity data has been misused to steal bank account details. [36] Mobile payment accounts have been subject to fraud. [37] Social media giants have gained consent to use personal data for one purpose but then used it for another. [38] There is an increasing awareness, both from government regulators [39] and global campaigns, [40] that this innovation train needs slowing down.
The UNs’ 2013 call for a data revolution [41] and the publishing in 2014 of A World That Counts [42] established a new priority for the role of data in meeting the SDGs between 2015 and 2020. In the past two years, with a few notable exceptions, [43] the term has almost entirely vanished. Some people argue that we have too much data and do not know how to use it. Some prefer, pedantically, to talk about evolution rather than revolution. Others have, from the start, seen it primarily as a technological phenomenon and are more persuaded by the “fourth industrial revolution”.
DI has been involved behind the scenes in many of the working groups and committees of this initiative from the start. Back in 2015 we made our position clear:
“So what is so revolutionary about all this? It is the paradigm shift that is required for governments to recognise that national statistics on development must be based on disaggregated subnational data. Sustainable development requires sustainable data. This is a down-to-earth people-based revolution.”
Digital Impact, 2015. Adventures in the Data Revolution: What Revolution? Available at: https://digitalimpact.io/adventures-in-the-data-revolution-what-revolution
Our work since then has only strengthened this point of view. Ensuring that local governments and service providers are able, however modestly, to plan, manage and monitor their operations with the benefit of digital data that they themselves have collected requires a cultural, administrative and technical revolution.
In the action plan we prepared for the government of South Sudan, [44] we estimated that a spend of US$30 million over three years would provide a modest-yet-pragmatic start to secure the foundations of the national statistical system. This represents about 0.3% of the country’s domestic budget. [45] In a 2017 paper [46] we calculated that establishing and maintaining the nationwide Ugandan Bureau of Statistics’ Community Information System (which would have the effect of creating an annual population and household census) would cost approximately US$4 million per year, amounting to less than 0.05% of domestic expenditure. [47] In South Sudan it is expected that it will be up to the UN to seek out funding and in Uganda the programme was halted due to the government’s commitment to fund its 2014 census. In fact in most low and middle income countries the national statistical system is badly underfinanced.
The most thorough study of national statistical systems carried out in Africa by the Data for African Development Working Group concluded with the recommendation that governments should reduce donor dependency and take better ownership of financing:
“African governments should allocate more domestic funding to their NSO and statistical systems to smooth spending, maintain teams, and enhance independence.”
Center for Global Development, 2014. Delivering on a Data Revolution in Sub-Saharan Africa: Final report of the Data for African Development Working Group. Available at: www.cgdev.org/publication/ft/delivering-data-revolution-sub-saharan-africa
The problem would appear not to be a shortage of cash, but rather a lack of recognition of the transformative benefits of data. To those of us who are card-carrying members of the data revolution this seems remarkably short sighted. However, the challenge that we have failed to address with any degree of success is how the demand for data is stimulated across the highest levels of government.
Not only does this underinvestment stifle development planning but, more importantly, by depending on donor assistance, it undermines the sovereignty of a core national asset.
There is not a single low income country where financial investments in data and statistics from both domestic and international sources fully meet the country’s needs. In this resource-starved environment investment decisions are highly political. The poorer the country the greater is the role of foreign donors in influencing development decisions. The more fragile the country the greater is the role of the humanitarian agencies in bypassing long-term national priorities to deliver short-term operational gains.
Two decades ago the donor community convened in Monterey [48] and Rome [49] to commit to coordinate their efforts in harmony with ‘partner country’ priorities. They recognised ”the growing evidence that, over time, the totality and wide variety of donor requirements and processes for preparing, delivering, and monitoring development assistance are generating unproductive transaction costs for, and drawing down the limited capacity of, partner countries” and that “donors’ practices do not always fit well with national development priorities and systems”. Very little has changed. In every country we have visited we have found evidence of donors competing with each other, duplicating efforts and imposing their own interests on the systems they invest in.
Household surveys remain the most important source for a range of key demographic and socioeconomic statistics. There are three major international household survey programmes funded respectively by USAID, UNICEF and the World Bank. These have become increasingly similar. [50] In earlier research we found that two-thirds of the questions in the two most widely used surveys, Demographic and Health Survey (DHS) and MICS, [51] are either identical or similar enough to be practically comparable. Despite a commitment to the UN Statistical Commission five years ago [52] to work towards harmonisation, not only has no progress been made but in countries such as Nigeria and Bangladesh the surveys are conducted by competing national institutions [53] with no sharing or comparison of results.
In Nigeria the Child Protection Information Management System overlaps with the National Orphans and Vulnerable Children Management Information System. In Bangladesh the District Health Information System (DHIS2) overlaps with the Family Planning Management Information System and in the refugee camps in Cox’s Bazar the Early Warning, Alert and Response System is deployed despite DHIS2 having developed its own module tailor-made for the humanitarian operation. In Uganda the Ministry of Gender, Labour and Social Development maintains several overlapping systems supported by different donors.
In Zimbabwe we interviewed a nurse responsible for treating HIV and AIDS patients in rural clinics. At the end of each consultation she was required to fill in a form, but it was too long for her to complete properly. The reason for its length was that different donors had each added their own questions to meet their own interests.
Ironically in Zimbabwe a lack of harmonisation has benefitted the staff of ZimStat who, as civil servants, are poorly paid. Between 2009 and 2018 ZimStat conducted 32 different surveys, all donor funded. The US$50 per diem for fieldwork ensured that the agency’s statisticians were kept happy, even if the surveys themselves were of limited use.
The commitment towards harmonisation is stretched even further when it comes to humanitarian operations. We first experienced this in the West Nile region of Uganda where humanitarian agencies flew in and bypassed the considerable resources and experience of district governments. In South Sudan agencies have created their own parallel data ecosystem with what amounts to a national data portal being managed from the UN Office for the Coordination of Humanitarian Affairs (OCHA)’s Humanitarian Data Centre in the Netherlands. [54]
There are always explanations as to why donors and international agencies choose to do their own things: the operational situation requires a fast response; a recipient government is perceived to be weak or corrupt; funding depends on the donor country pursuing its own national interests.
Our answer to this is to be found in the conclusion of our South Sudan study:
“There may well appear to be a compelling argument that the reason why official statistics are not a priority in South Sudan, for either government or international agencies, is the scale of the challenges facing the country and the fact that peace and recovery have to come first. But this is to miss the important truth that good quality, reliable and relevant official statistics – and good use of those statistics – are key in any recovery and reconstruction effort. And if this is true, then the strengthening of sustainable national capacity to own and manage national data infrastructure and official statistics should be at the heart of the security, humanitarian and development agendas in South Sudan.”
DI, forthcoming. Meeting the SDGs in South Sudan: The data landscape.
There is an increasing demand for the type of action-oriented research we have described. Governments are increasingly interested in the power of data to strengthen local government and we look forward to furthering our experience in this arena and challenging the growing list of assumptions that we take from one job to the next. Our three biggest learnings, we believe, will remain unchallenged.
Firstly, governments need to own their own problems and solutions. They need to own their own data on behalf of their citizens. And for this to be sustainable they need to finance it.
Secondly, this is all about people. Counting people – people living in poverty, left behind and dispossessed – so that they do indeed count is the primary challenge. And people – from the lowliest primary health care assistant to the chief statistician – are at the heart of the solution.
And thirdly, we need to learn how to create a perpetual virtuous cycle at all levels where better use of data leads to demands for more and better quality data which leads to demands for more use of data.
When we were working in South Sudan the staff of the National Bureau of Statistics had not been paid for six months, yet they were still turning up for work, resolved to build their country’s data ecosystem. We will continue to champion their cause, and the struggling statisticians in many low income countries, with the respect they deserve from us all.
Downloads
Notes
-
1
Development Initiatives (DI), 2015. Adventures in the Data Revolution. Available at: /what-we-do/news/adventures-in-the-data-revolutionReturn to source text
-
2
DI, 2014. Using resource tracking and feedback to enhance accountability and resource effectiveness. Available at: http://devinit.org/wp-content/uploads/2014/11/Africa-Evidence-Network-paper1.pdfReturn to source text
-
3
DI, 2017. Citizen-generated data and sustainable development: Evidence from case studies in Kenya and Uganda. Available at: /resources/citizen-generated-data-and-sustainable-development-evidence-from-case-studies-in-kenya-and-uganda-2Return to source text
-
4
DI, 2016. Uganda’s data ecosystem. Available at: /resources/ugandas-data-ecosystemReturn to source text
-
5
DI, 2017. The Development Data Assessment. Available at: /resources/development-data-assessmentReturn to source text
Related content
Data disharmony: How can donors better act on their commitments?
This briefing highlights key challenges emerging from our work analysing national data ecosystems, and aims to promote discussion between relevant stakeholders on how best to overcome these.
How can data better support disability advocacy in East Africa?
In this podcast DI's Claudia Wells is joined by guests from DI, Sightsavers and the United Disabled Persons of Kenya to discuss how better data can empower disability advocates in East Africa.
Digital civil registration and legal identity systems: A joined-up approach to leave no one behind
An overview of trends in civil registration and vital statistics (CRVS). To deliver the Sustainable Development Goals (SDGs), how can we ensure everyone is counted?